用 Sql Server Profiler 来跟踪页面访问的时 SQL 的执行情况,因为应用程序很简单,页面加载的时候,跟踪检测到三个 SQL 执行,看了下也没什么问题(两个获取数量,一个获取列表),数量获取的 SQL,这个应该执行会很快,所以把分析焦点放在了那个获取列表的 SQL 上,因为 SQL 没什么问题,那应该是关于这条 SQL 建的索引有问题。注:上面所说项目中大概有 100 万的数据。
关于数据库中的索引概念,记得在很早之前整理了一篇博文《T-Sql(八)字段索引和数据加密》,现在来看,写的真是一坨屎,概念讲的再多没个毛用,关键在于对实际应用中产生问题的分析。在研究这个问题之前,搜了一些相关资料,主要来自园中的几位 SQL Server 大神(CareySon、桦仔、听风吹雨等),稍微看了下,关于索引,主要是一些数据库专业术语,看的不是很明白,作为程序员,我们知道索引分为聚集性索引和非聚集性索引,聚集性索引一般为主键(也可以不是),在创建表的时候会自动创建,针对上面我那个应用查询问题,查询条件是一些非主键字段,所以这边探讨下非聚集性索引。
我不会说一些数据库概念,所以只能用做一些实践来理解概念的意义,以下应用场景中的用例是虚拟出来的,只是作为个人研究使用。
程序员应该有刨根问底的怪癖,虽然这是个数据库问题。
应用场景
有一个 Product 表,字段如下:
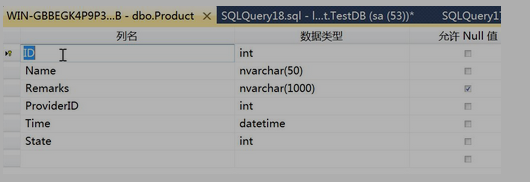
数据添加脚本:
begin tran
declare @index int
set @index=0
while(@index<1000000)
begin
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题1','我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1',1,GETDATE(),0)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题2','我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2',1,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题3','我是测试备注3',3,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题4','我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4',4,GETDATE(),1)
set @index=@index+1
end
commit
Product 表中插入了四百万的数据,为了接近我们现实生产环境,所以对数据进行了不同插入。
一般应用环境查询,有时候我们会针对一个字段进行 where 查询,有时候也会 and 另一个字段进行查询,这个时候,关于这两个字段的索引怎么建?还是不需要建?是分别建两个?还是建一个组合的?其实说真的,可能看到这的数据库大神会莞尔一笑,但是作为程序员,这些我真不知道,搜索的资料中也并没有对这些鸡毛蒜皮进行的说明,没办法,只能自己瞎折腾下。我们下面要做是 ProviderID 和 State 的查询操作,有分别查询,也有组合查询,然后我们再对 Product 表建立这两个字段的索引,看看有什么不同之处?还有就是针对不同的索引方式,查询又会有什么不同?我们睁大眼睛来看一下。
问题分析
我再对上面的分析进行说明下,首先,查询主要为2种:
where ProviderID=?
where ProviderID=? and State=?
非聚集性索引的创建主要为3种:
不创建索引
ProviderID 字段索引
ProviderID 和 State 字段索引
针对这个应用场景和上面的分析,会得出 3*2 六种结果,其实我最想知道的是下面的第三种,即创建一个组合字段索引,对单个字段的查询会不会有影响?还有就是反过来,单个字段的索引创建,对组合字段查询会不会有影响?当然试过了才知道,看一下执行结果。
执行结果
测试脚本:
declare @begin_date datetime
declare @end_date datetime
select @begin_date = getdate()
select * from [dbo].[Product] where ...
select @end_date = getdate()
select datediff(ms,@begin_date,@end_date) as '用时/毫秒'
为了接近测试结果,每次语句执行三次,然后再取平均值,截图太麻烦了,这边就直接贴下执行结果。
不创建索引
where ProviderID=1(二百万数据)
执行结果:13806毫秒,13380毫秒,12730毫秒
平均结果:13305毫秒
where ProviderID=1 and State=1(一百万数据)
执行结果:6556毫秒,6613毫秒,6706毫秒
平均结果:6625毫秒
创建索引字段 ProviderID
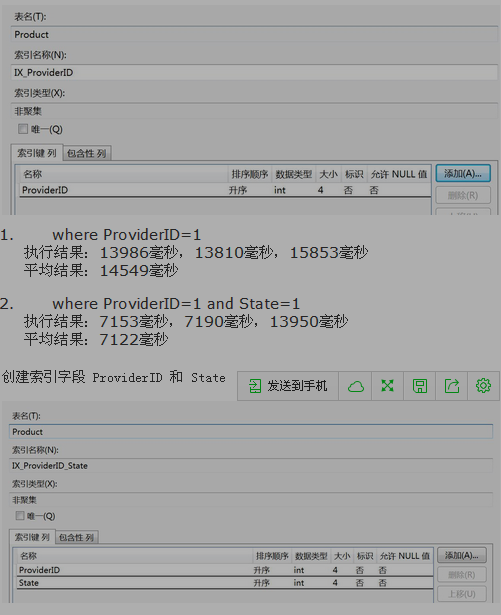
where ProviderID=1
执行结果:13840毫秒,14163毫秒,15853毫秒
平均结果:14618毫秒
where ProviderID=1 and State=1
执行结果:7033毫秒,7220毫秒,7023毫秒
平均结果:7152毫秒
结果分析
虽然测试的有些不完整,但是看到结果,哥有些凌乱了(建了索引,性能反而会降低?),难道是我插入的数据有问题?还是创建索引有问题?还是我人品有问题???坐等数据库大神指教。
更多信息请查看IT技术专栏