为什么要有缓存
应用需要离线工作的主要原因就是改善应用所表现出的性能。将应用内容缓存起来就可以支持离线。我们可以用两种不同的缓存来使应用离线工作。第一种是**按需缓存**,这种情况下应用缓存起请求应答,就和Web浏览器的工作原理一样;第二种是**预缓存**,这种情况是缓存全部内容(或者最近n条记录)以便离线访问。
像第14章中开发的Web服务应用利用按需缓存技术来改善可感知的性能而不是提供离线访问。离线访问只是无心插柳的结果。Twitter和Foursquare就是很好的例子。这类应用得到的数据通常很快就会过时。对于一条几天前的推文或者朋友上周在哪里你能有多大兴趣?一般来说,一条推文或者一条签到的信息只在几个小时内有意义,而24小时之后就变得无关紧要。不过大部分Twitter客户端还是会缓存推文,而Foursquare的官方客户端在无网络连接的情况下打开,会显示上次的状态。
大家可以用自己喜欢的Twitter客户端来试一下,Twitter for iPhone、Tweetbot或其他应用:打开某个朋友的个人资料并浏览他的时间线。应用会获取时间线并填充页面。加载时间线时会看到一个表示正在加载的圆圈在旋转。现在进入另一个页面,然后再回来打开时间线。你会发现这次是瞬间加载的。应用还是在后台刷新内容(在上次打开的基础上),但是它会显示上次缓存的内容而不是无趣地转圈,这样看起来就快多了。如果没有缓存,用户每次打开一个页面都会看到圆圈在旋转。无论网络连接快还是慢,减小网络加载慢的影响,让它看起来很快,是iOS开发者的责任。这就能大大改善用户满意度,从而提高了应用在App Store中的评分。
另一种缓存更加重视被缓存数据,并且能快速编辑被缓存的记录而无需连接到服务器。代表应用包括Google Reader客户端,稍后阅读类的应用Instapaper等。
缓存的策略:
上一节中讨论到按需缓存和预缓存,它们在设计和实现上有很大的不同。按需缓存是指把从服务器获取的内容以某种格式存放在本地文件系统,之后对于每次请求,检查缓存中是否存在这块数据,只有当数据不存在(或者过期)的情况下才从服务器获取。这样的话,缓存层就和处理器的高速缓存差不多。获取数据的速度比数据本身重要。而预缓存是把内容放在本地以备将来访问。对预缓存来说,数据丢失或者缓存不命中是不可接受的,比方用户下载了文章准备在地铁上看,但却发现设备上不存在这些文章。
像Twitter、Facebook和Foursquare这样的应用属于按需缓存,而Instapaper和Google Reader等客户端则属于预缓存。
实现预缓存可能需要一个后台线程访问数据并以有意义的格式保存,以便本地缓存无需重新连接服务器即可被编辑。编辑可能是“标记记录为已读”或“加入收藏”,或其他类似的操作。这里**有意义的格式**是指可以用这种方式保存内容,不用和服务器通信就可以在本地作出上面提到的修改,并且一旦再次连上网就可以把变更发送回服务器。这种能力和Foursquare等应用不同,虽然使用后者你能在无网络连接的情况下看到自己是哪些地点的地主(Mayor),当然前提是进行了缓存,但无法成为某个地点的地主。Core Data(或者任何结构化存储)是实现这种缓存的一种方式。
按需缓存工作原理类似于浏览器缓存。它允许我们查看以前查看或者访问过的内容。按需缓存可以通过在打开一个视图控制器时按需地缓存数据模型(创建一个数据模型缓存)来实现,而不是在一个后台线程上做这件事。也可以在一个URL请求返回成功(200 OK)应答时实现按需缓存(创建一个URL缓存)。两种方法各有利弊,稍后我会在24.3节和24.6节中解释各个方法的优缺点。
选择使用按需缓存还是预缓存的一个简便方法是判断是否需要在下载数据之后处理数据。后期处理数据可能是以用户产生编辑的形式,也可能是更新下载的数据,比如重写HTML页面里的图片链接以指向本地缓存图片。如果一个应用需要做上面提到的任何后期处理,就必须实现预缓存。
存储缓存:
第三方应用只能把信息保存在应用程序的沙盒中。因为缓存数据不是用户产生的,所以它应该被保存在NSCachesDirectory,而不是NSDocumentsDirectory。为缓存数据创建独立目录是一项不错的实践。在下面的例子中,我们将在Library/caches文件夹下创建名为MyAppCache的目录。可以这样创建:
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
cachesDirectory = [cachesDirectory
stringByAppendingPathComponent:@"MyAppCache"];
把缓存存储在缓存文件夹下的原因是iCloud(和iTunes)的备份不包括此目录。如果在Documents目录下创建了大尺寸的缓存文件,它们会在备份的时候被上传到iCloud并且很快就用完有限的空间(写作本书时大约为5 GB)。你不会这么干的——谁不想成为用户iPhone上的良民?NSCachesDirectory正是解决这个问题的。
预缓存是用高级数据库(比如原始的SQLite)或者对象序列化框架(比如Core Data)实现的。我们需要根据需求认真选择不同的技术。本节第5点“应该用哪种缓存技术”给出了一些建议:什么时候该用URL缓存或者数据模型缓存,而什么时候又该用Core Data。接下来先看一下数据模型缓存的实现细节。
1. 实现数据模型缓存
可以用NSKeyedArchiver类来实现数据模型缓存。为了把模型对象用NSKeyedArchiver归档,模型类需要遵循NSCoding协议。
NSCoding协议方法
- (void)encodeWithCoder:(NSCoder *)aCoder; - (id)initWithCoder:(NSCoder *)aDecoder;
当模型遵循NSCoding协议时,归档对象就很简单,只要调用下列方法中的一个:
[NSKeyedArchiver archiveRootObject:objectForArchiving
toFile:archiveFilePath];
[NSKeyedArchiver archivedDataWithRootObject:objectForArchiving];
第一个方法在archiveFilePath指定的路径下创建一个归档文件。第二个方法则返回一个NSData对象。NSData通常更快,因为没有文件访问开销,但对象保存在应用的内存中,如果不定期检查的话会很快用完内存。在iPhone上定期缓存到闪存的功能也是不明智的,因为跟硬盘不同,闪存读写寿命是有限的。开发者得尽可能平衡好两者的关系。24.3节会详细介绍归档实现缓存。
NSKeyedUnarchiver类用于从文件(或者NSData指针)反归档模型。根据反归档的位置,选择使用下面两个类方法。
[NSKeyedUnarchiver unarchiveObjectWithData:data];
[NSKeyedUnarchiver unarchiveObjectWithFile:archiveFilePath];
这四个方法在转化序列化数据时能派上用场。
使用任何NSKeyedArchiver/NSKeyedUnarchiver的前提是模型实现了NSCoding协议。不过要做到这一点很容易,可以用Accessorizer类工具自动实现NSCoding协议。(24.8节列出了Accessorizer在Mac App Store中的链接。)
下一节会解释预缓存策略。我们刚才已经了解到预缓存需要用到更结构化的数据格式,接下来看看Core Data和SQLite。
2. Core Data
正如Marcus Zarra所说,Core Data更像是一个对象序列化框架,而不仅仅是一个数据库API:
大家误认为Core
Data是一个Cocoa的数据库API……其实它是个可以持久化到磁盘的对象框架(Zarra,2009年)。
要深入理解Core Data,看一下Marcus S. Zarra写的*Core Data: Apple's API for Persisting Data on Mac OS X*(Pragmatic Bookshelf, 2009. ISBN 9781934356326)。
要在Core Data中保存数据,首先创建一个Core Data模型文件,并创建实体(Entity)和关系(Relationship);然后写好保存和获取数据的方法。应用可以借助Core Data获取真正的离线访问功能,就像苹果内置的Mail和Calendar应用一样。实现预缓存时必须定期删除不再需要的(过时的)数据,否则缓存会不断增长并影响应用的性能。同步本地变更是通过追踪变更集并发送回服务器实现的。变更集的追踪有很多算法,我推荐的是Git版本控制系统所用的(此处没有涉及如何与远程服务器同步缓存,这不在本书讨论范围之内)。
3. 用Core Data实现按需缓存
尽管从技术上讲可以用Core Data来实现按需缓存,但我不建议这么做。Core Data的优势是不用反归档完整的数据就可以独立访问模型的属性。然而,在应用中实现Core Data带来的复杂度抵消了优势。此外,对于按需缓存实现来说,我们可能并不需要独立访问模型的属性。
4. 原始的SQLite
可以通过链接libsqlite3的库来把SQLite嵌入应用,但是这么做有很大的缺陷。所有的sqlite3库和对象关系映射(Object Relational Mapping,ORM)机制几乎总是会比Core Data慢。此外,尽管sqlite3本身是线程安全的,但是iOS上的二进制包则不是。所以除非用定制编译的sqlite3库(用线程安全的编译参数编译),否则开发者就有责任确保从sqlite3读取数据或者往sqlite3写入数据是线程安全的。Core Data有这么多特性而且内置线程安全,所以我建议在iOS中尽量避免使用SQLite。
唯一应该在iOS应用中用原始的SQLite而不用Core Data的例外情况是,资源包中有应用程序相关的数据需要在所有应用支持的第三方平台上共享,比如说运行在iPhone、Android、BlackBerry和Windows Phone上的某个应用的位置数据库。不过这也不是缓存了。
5. 应该用哪种缓存技术
在众多可以本地保存数据的技术中,有三种脱颖而出:URL缓存、数据模型缓存(利用NSKeyedArchiver)和Core Data。
假设你正在开发一个应用,需要缓存数据以改善应用表现出的性能,你应该实现按需缓存(使用数据模型缓存或URL缓存)。另一方面,如果需要数据能够离线访问,而且具有合理的存储方式以便离线编辑,那么就用高级序列化技术(如Core Data)。
6. 数据模型缓存与URL缓存
按需缓存可以用数据模型缓存或URL缓存来实现。两种方式各有优缺点,要使用哪一种取决于服务器的实现。URL缓存的实现原理和浏览器缓存或代理服务器缓存类似。当服务器设计得体,遵循HTTP 1.1的缓存规范时,这种缓存效果最好。如果服务器是SOAP服务器(或者实现类似于RPC服务器或RESTful服务器),就需要用数据模型缓存。如果服务器遵循HTTP 1.1缓存规范,就用URL缓存。数据模型缓存允许客户端(iOS应用)掌控缓存失效的情形,当开发者实现URL缓存时,服务器通过HTTP 1.1的缓存控制头控制缓存失效。尽管有些程序员觉得这种方式违反直觉,而且实现起来也很复杂(尤其是在服务器端),但这可能是实现缓存的好办法。事实上,MKNetworkKit提供了对HTTP 1.1缓存标准的原生支持。
数据模型缓存:
本节我们来给第14章中的iHotelApp添加用数据模型缓存实现的按需缓存。按需缓存是在视图从视图层次结构中消失时做的(从技术上讲,是在viewWillDisappear:方法中)。支持缓存的视图控制器的基本结构如图24-1所示。AppCache Architecture的完整代码可从本章的下载源代码中找到。后面讲解的内容假设你已经下载了代码并且可以随时使用。
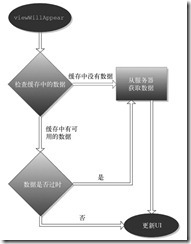
图24-1
实现了按需缓存的视图控制器的控制流
在viewWillAppear方法中,查看缓存中是否有显示这个视图所需的数据。如果有就获取数据,再用缓存数据更新用户界面。然后检查缓存中的数据是否已经过期。你的业务规则应该能够确定什么是新数据、什么是旧数据。如果内容是旧的,把数据显示在UI上,同时在后台从服务器获取数据并再次更新UI。如果缓存中没有数据,显示一个转动的圆圈表示正在加载,同时从服务器获取数据。得到数据后,更新UI。
前面的流程图假定显示在UI上的数据是可以归档的模型。在iHotelApp的MenuItem模型中实现NSCoding协议。NSKeyedArchiver需要模型实现这个协议,如下面的代码片段所示。
MenuItem类的encodeWithCoder方法(MenuItem.m)
- (void)encodeWithCoder:(NSCoder *)encoder
{
[encoder encodeObject:self.itemId forKey:@"ItemId"];
[encoder encodeObject:self.image forKey:@"Image"];
[encoder encodeObject:self.name forKey:@"Name"];
[encoder encodeObject:self.spicyLevel forKey:@"SpicyLevel"];
[encoder encodeObject:self.rating forKey:@"Rating"];
[encoder encodeObject:self.itemDescription forKey:@"ItemDescription"];
[encoder encodeObject:self.waitingTime forKey:@"WaitingTime"];
[encoder encodeObject:self.reviewCount forKey:@"ReviewCount"];
}
MenuItem类的initWithCoder方法(MenuItem.m)
- (id)initWithCoder:(NSCoder *)decoder
{if ((self = [super init])) {
self.itemId = [decoder decodeObjectForKey:@"ItemId"];
self.image = [decoder decodeObjectForKey:@"Image"];
self.name = [decoder decodeObjectForKey:@"Name"];
self.spicyLevel = [decoder decodeObjectForKey:@"SpicyLevel"];
self.rating = [decoder decodeObjectForKey:@"Rating"];
self.itemDescription = [decoder
decodeObjectForKey:@"ItemDescription"];
self.waitingTime = [decoder decodeObjectForKey:@"WaitingTime"];
self.reviewCount = [decoder decodeObjectForKey:@"ReviewCount"];
}return self;
}
就像之前提到过的,可以用Accessorizer来生成NSCoding协议的实现。
根据图24-1中的缓存流程图,我们需要在viewWillAppear:中实现实际的缓存逻辑。把下面的代码加入viewWillAppear:就可以实现。
视图控制器的viewWillAppear:方法中从缓存恢复数据模型对象的代码片段
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
NSString *archivePath = [cachesDirectory
stringByAppendingPathComponent:@"AppCache/MenuItems.archive"];
NSMutableArray *cachedItems = [NSKeyedUnarchiver
unarchiveObjectWithFile:archivePath];if(cachedItems == nil)
self.menuItems = [AppDelegate.engine localMenuItems];else
self.menuItems = cachedItems;
NSTimeInterval stalenessLevel = [[[[NSFileManager defaultManager]
attributesOfItemAtPath:archivePath error:nil]
fileModificationDate] timeIntervalSinceNow];if(stalenessLevel > THRESHOLD)
self.menuItems = [AppDelegate.engine localMenuItems];
[self updateUI];
缓存机制的逻辑流如下所示。
视图控制器在归档文件MenuItems.archive中检查之前缓存的项并反归档。
如果MenuItems.archive不存在,视图控制器调用方法从服务器获取数据。
如果MenuItems.archive存在,视图控制器检查归档文件的修改时间以确认缓存数据有多旧。如果数据过期了(由业务需求决定),再从服务器获取一次数据。否则显示缓存的数据。
接下来,把下面的代码加入viewDidDisappear方法可以把模型(以NSKeyedArchiver的形式)保存在Library/Caches目录中。
视图控制器的viewWillDisappear:方法中缓存数据模型的代码片段
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,
NSUserDomainMask, YES);
NSString *cachesDirectory = [paths objectAtIndex:0];
NSString *archivePath = [cachesDirectory stringByAppendingPathComponent:@" AppCache/MenuItems.archive"];
[NSKeyedArchiver archiveRootObject:self.menuItems toFile:archivePath];
视图消失时要把menuItems数组的内容保存在归档文件中。注意,如果不是在viewWillAppear:方法中从服务器获取数据的话,这种情况不能缓存。
所以,只需在视图控制器中加入不到10行的代码(并将Accessorizer生成的几行代码加入模型),就可以为应用添加缓存支持了。
重构
当开发者有多个视图控制器时,前面的代码可能会有冗余。我们可以通过抽象出公共代码并移入名为AppCache的新类来避免冗余。AppCache是处理缓存的应用的核心。把公共代码抽象出来放入AppCache可以避免viewWillAppear:和viewWillDisappear:中出现冗余代码。
重构这部分代码,使得视图控制器的viewWillAppear/viewWillDisappear代码块看起来如下所示。加粗部分显示重构时所做的修改,我会在代码后面解释。
视图控制器的viewWillAppear:方法中用AppCache类缓存数据模型的重构代码片段(MenuItemsViewController.m)
-(void) viewWillAppear:(BOOL)animated {
self.menuItems = [AppCache getCachedMenuItems];
[self.tableView reloadData];if([AppCache isMenuItemsStale] || !self.menuItems) {
[AppDelegate.engine fetchMenuItemsOnSucceeded:^(NSMutableArray *listOfModelBaseObjects) {
self.menuItems = listOfModelBaseObjects;
[self.tableView reloadData];
} onError:^(NSError *engineError) {
[UIAlertView showWithError:engineError];
}];
}
[super viewWillAppear:animated];
} -(void) viewWillDisappear:(BOOL)animated {
[AppCache cacheMenuItems:self.menuItems];
[super viewWillDisappear:animated];
}
AppCache类把判断数据是否过期的逻辑从视图控制器中抽象出来了,还把缓存保存的位置也抽象出来了。稍后在本章中我们还会修改AppCache,再引入一层缓存,内容会保存在内存中。
因为AppCache抽象出了缓存的保存位置,我们就不需要为复制粘贴代码来获得应用的缓存目录而操心了。如果应用类似于iHotelApp,开发者可通过为每个用户创建子目录即可轻松增强缓存数据的安全性。然后我们就可以修改AppCache中的辅助方法,现在它返回的是缓存目录,我们可以让它返回当前登录用户的子目录。这样,一个用户缓存的数据就不会被随后登录的用户看到了。
完整的代码可以从本书网站上本章的源代码下载中获取。
缓存版本控制:
我们在上一节中写的AppCache类从视图控制器中抽象出了按需缓存。当视图出现和消失时,缓存就在幕后工作。然而,当你更新应用时,模型类可能会发生变化,这意味着之前归档的任何数据将不能恢复到新的模型上。正如之前所讲,对按需缓存来说,数据并没有那么重要,开发者可以删除数据并更新应用。我会展示可以用来在版本升级时删除缓存目录的代码片段。
iOS中验证模型:
第二个是验证模型,服务器通常会发送一个校验和(Etag)。后续所有从缓存获得资源的请求都应该用这个校验和向服务器**重新验证**资源是否有变化。如果校验和匹配,服务器就返回一个HTTP 304 Not Modified的状态码。
IOS内存缓存:
目前为止,所有iOS设备都带有闪存,而闪存有点小问题:它的读写寿命是有限的。尽管这个寿命跟设备的使用寿命比起来很长,但是仍然需要避免过于频繁地读写闪存。在上一个例子中,视图隐藏时是直接缓存到磁盘的,而视图显示时又是直接从磁盘读取的。这种行为会使用户设备的缓存负担很重。为避免这个问题,我们可以再引入一层缓存,利用设备的RAM而不是闪存(用NSMutableDictionary)。在24.2.1节的“实现数据模型缓存”中,我们介绍了创建归档的两种方法:一个是保存到文件,另一个是保存为NSData对象。这次会用到第二个方法,我们会得到一个NSData指针,将该指针保存到NSMutableDictionary中,而不是文件系统里的平面文件。引入内存缓存的另一个好处是,在归档和反归档内容时性能会略有提升。听起来很复杂,实际上并不复杂。本节将介绍如何给AppCache类添加一层透明的、位于内存中的缓存。(“透明”是指调用代码,即视图控制器,甚至不知道这层缓存的存在,而且也不需要改动任何代码。)我们还会设计一个LRU(Least Recently Used,最近最少使用)算法来把缓存的数据保存到磁盘。
以下简单列出了要创建内存缓存需要的步骤。这些步骤将会在下面几节中详细解释。
添加变量来存放内存缓存数据。
限制内存缓存大小,并且把最近最少使用的项写入文件,然后从内存缓存中删除。RAM是有限的,达到使用极限就会触发内存警告。收到警告时不释放内存会使应用崩溃。我们当然不希望发生这种事,所以要为内存缓存设置一个最大阈值。当缓存满了以后再添加任何东西时,最近最少使用的对象应该被保存到文件(闪存中)。
处理内存警告,并把内存缓存以文件形式写入闪存。
当应用关闭、退出,或进入后台时,把内存缓存全部以文件形式写入闪存。
更多信息请查看IT技术专栏