Failure-Atomic Updates of Application Data in a Linux File System
本论文主要设计并实现了一种能保护应用数据原子性的文件系统,其通过扩展 POSIX 接口来完成这个能力。其背景主要是传统文件系统通常使用日志形式来保证自身元数据的正确性,来避免掉电或者系统崩溃后造成的文件系统异常,而应用程序数据为了保证数据更新的原子性和正确性必须在应用层同样实现日志功能。
为了解决应用层使用日志引起的 Double Write,目前硬件厂商比如 Fushion IO 提供的原子写 API 或者使用 NVM 来保证持久性的内存写入来解决系统崩溃带来的问题。
本文的 AdvFS 完全不依赖特定硬件并且基于原生的内核实现了支持原子更新且支持多文件的原子更新。在打开一个 AdvFS 的文件时指定 O_ATOMIC 来表示该文件需要使用原子更新能力,在打开文件后会在 AdvFS 产生一个 shadow file,其是用户可见文件的 clone,其跟正常文件一样指向数据块,但是拥有自己的数据指针图,在写入文件时使用 COW(copy on write) 技术正常文件的数据指针图更新到写入到新的块,在调用 msync 时会删除原来 clone 指针图和相应的数据块,同时产生一个新的 clone。最后在关闭文件,会删除该 clone。因此如果系统发生崩溃,在打开该文件时会发现残留的 clone 文件,可以恢复到之前的内容来保证更新一致性。
如果更新多个文件时,因为单文件使用 COW 的形式提供原子性,那么多文件其利用日志来记录元数据操作,比如写入后同步会对日志写入所有相关的 clone 元数据操作,且不会写入数据内容,因此可以利用较少的日志空间大小得到同时能够原子性更新多个文件的效果。
最后通过 AuvFS 跟其他文件系统使用 Double Write 获得的原子性更新做比较,在传统的 B树数据库能获得较大收益,对于 LevelDB 等 LSM 结构的数据库会造成性能下降,对于了解两者实现的性能差异我们可以很容易理解。
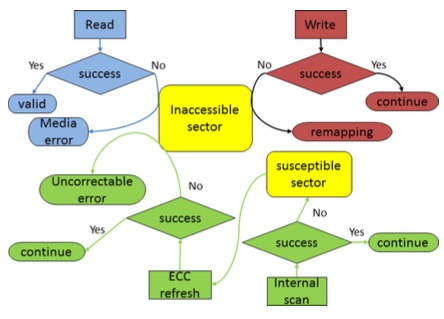
RAIDShield: Characterizing, Monitoring, and Proactively Protecting Against Disk Failures
本论文旨在通过监测物理盘的内部统计数据的变化来进行分析并判断一个 RAID 盘阵是否处于不健康状态。众所周知,RAID 通过冗余数据增加了数据的可用性和持久性,但是在运行过程中的数据访问和修改会使得不同盘组迥异的数据可用结果和状态。
本文提出了两种监测模式,一种是独立盘的内部数据如 Sector Error,Reallocated Sector 等,类似于设置一个阀值,当错误量超过一定数目时进行报警。另一种是通过多个盘的联合监测并通过公式计算盘组的数据访问有效性来解决当多个盘可能同时到达阀值而短时间无法更换大量盘的问题。
该文对于分布式存储提供了一定的借鉴意义,单个盘的错误数据可以有效帮助管理员提前预警,多个盘的联合监测能提高集群应对极端情况的应对能力。
F2FS: A New File System for Flash Storage
F2FS 在文件系统届应该是小有名气的了,作为以面向 SSD 优化著称的本地文件系统,它在论文中介绍了其对于 Flash SSD 的特点与传统文件系统实现的差异,然后横向比较了与 Ext4(Update in Place)、Btrfs(Copy on Write) 和 NILFS2(LFS) 的性能差异。
从其对特性的论述中如 Flash SSD 友好的 on-disk 格式,在更新数据时减小对于元数据更新的损耗(减小随机小 IO),用多个 logging 流来提高并发能力,同时支持两种写日志方式(Append-only 和 Write in Hole)来解决高利用率时前者性能雪崩问题,最后还有面向大量使用 fsync 程序如 SQLite 的 fsync 调用优化。
总的而言,F2FS 采用了空间换时间的策略,在实现上对于潜在的大量随机 IO 等待大量使用 Lazy 的策略处理,同时因为采用 Lazy 的原因对于在高利用率下的压测可能造成 Cleaning 延时的问题上,保留了 5% 的预留空间来避免潜在的雪崩情况。打个比喻,F2FS 把大多数传统文件系统(或者 LFS)可能的随机小 IO 都不会及时提交而是拖后合并,这些小 IO 实际上可能累积后在最后的低可用空间先造成雪崩,但是 F2FS 的预留空间好像是“救命稻草”一样简单利落的扼杀了这种风险,非常对本人的”胃口”:-)。
A Practical Implementation of Clustered Fault Tolerant Write Acceleration in a Virtualized Environment
这篇论文是希望在 VM 的 Host 端提供写缓存来加速 VM IO,但是我们知道在 VM 存储使用共享存储方式时可以得到 Live Migration 这个使 VM 能够具备移动能力,避免单机故障。而如果在 Host 端加入缓存,无疑使得 Live Migration 无法使用。因此,本文尝试在所有 Host 上建立一个写缓存”集群”来解决这个问题,使得每次写在本地的缓存会同步发到另一个 Host,这样使得在 Host 挂掉后仍可以在其他机器启动 VM。
老实说,类似架构可在 Nutanix 的存储设计中得到引用,但是为了提供写缓存的高可用性而构建这么一个复杂的 Host Side 写缓存集群似乎不只增加了一点复杂性。
BetrFS: A Right-Optimized Write-Optimized File System
看完概要就发现这是个利用 BufferTree 来实现的本地文件系统,采用的是 TokuDB 的 Ft-index。对于 Ft-index 有兴趣的可以看看其本身的 paper,本文主要是做了将 Ft-index 迁移到内核并对接 VFS 进行了一番工作。
更多信息请查看IT技术专栏