本文分析了ucenter中词语过滤原理。分享给大家供大家参考,具体如下:
过滤词语表:
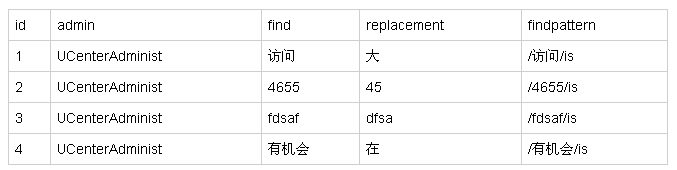
组建缓存数据:
//private
function _get_badwords() {
$data = $this->db->fetch_all("SELECT * FROM ".UC_DBTABLEPRE."badwords");
$return = array();
if(is_array($data)) {
foreach($data as $k => $v) {
$return['findpattern'][$k] = $v['findpattern'];
$return['replace'][$k] = $v['replacement'];
}
}
return $return;
}
调用方法:
$_CACHE['badwords'] = $this->base->cache('badwords');
if($_CACHE['badwords']['findpattern']) {
$subject = @preg_replace($_CACHE['badwords']['findpattern'], $_CACHE['badwords']['replace'], $subject);
$message = @preg_replace($_CACHE['badwords']['findpattern'], $_CACHE['badwords']['replace'], $message);
}
preg_replace() 的每个参数(除了 limit)都可以是一个数组。如果 pattern 和 replacement 都是数组,将以其键名在数组中出现的顺序来进行处理。这不一定和索引的数字顺序相同。如果使用索引来标识哪个 pattern 将被哪个 replacement 来替换,应该在调用 preg_replace() 之前用 ksort() 对数组进行排序。
希望本文所述对大家PHP程序设计有所帮助。